
Day in, day out, media outlets report an escalating electricity shortage across developed countries, and data centers often lie at the heart of these discussions. An often-repeated analogy compares the annual energy consumption of the largest data centers to that of major cities or even small countries. Compounding the issue are rising concerns that rural communities near these data centers may be suffering from mysterious health problems, potentially linked to noise pollution from the centers’ cooling systems. These effects seem to impact not just humans but also local pets and wildlife.1
At its core, this problem is rooted in the fundamental laws of physics: electrical power, when transmitted through conductors, inevitably dissipates energy—the longer the conductor, the greater the energy lost.
A decade-old study led by Professor Mark Horowitz at Stanford University quantified the considerable energy losses inherent in electronic processing. Table I provides details:
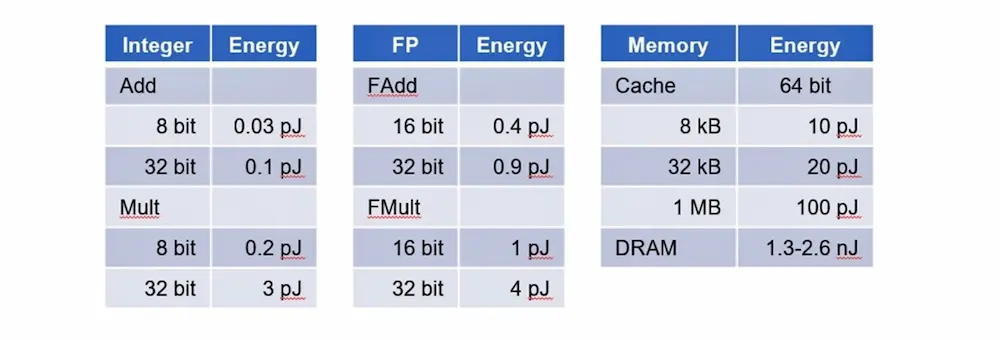
Table I: Energy dissipation across components varies widely from less than one picojoule for integer arithmetic in adders and multipliers to several picojoules for floating-point operations. Memory access proves even more costly: retrieving data from cache consumes 20 to 100 picojoules while accessing DRAM jumps by up to three orders of magnitude surpassing 1,000 picojoules. Published with permission from Prof. Mark Horowitz at Stanford University.
In essence, the study revealed that memory systems can dissipate up to one thousand times more energy than the logic used for processing data.
Memory: The roadblock to ultimate efficiency
High power dissipation during memory operations has led to a widening gap between progress in memory bandwidth versus advancement in data processing. This growing disparity, known as “memory wall,” severely hampers processor efficiency, as processors are forced to idle while waiting for data to be transferred from memory systems.2 The more powerful the processor, the longer the waiting time. Furthermore, as data volumes increase, processors idle even further, preventing processors from achieving full utilization and dramatically reducing overall processing efficiency. This inefficiency also drives up power consumption and limits system scalability.
To contain the fallback, the industry conceived a multi-level hierarchical memory architecture, placing faster (but more expensive) memory technologies between the processor and the DRAM memory banks. Moving up the hierarchy from the main memory, the storage capacity decreases, but the speed of data transfer increases significantly, namely, the number of clock cycles to move data drops dramatically. See Figure 1.
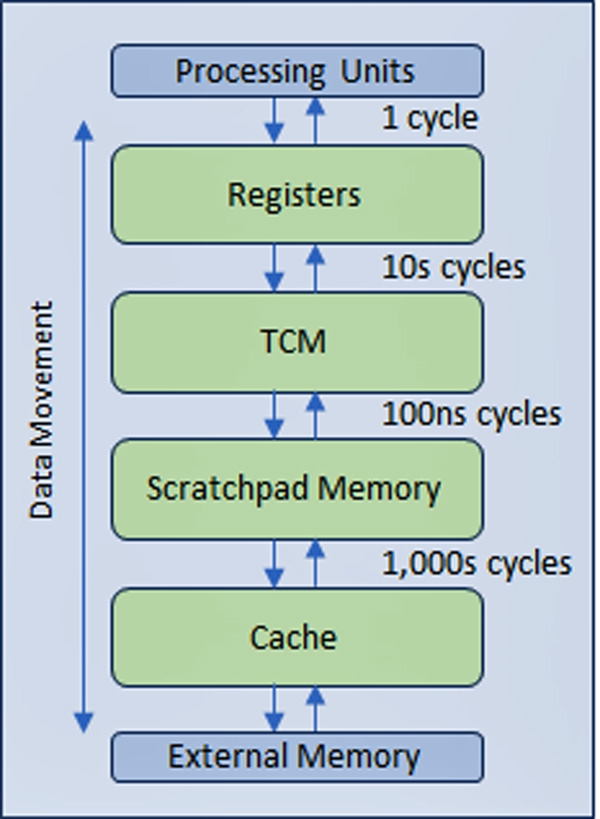
In an ideal scenario, collapsing the hierarchy into a sea of registers of equivalent capacity would result in significant acceleration, delivering efficiencies close to 100% while drastically reducing energy consumption.
AI applications demand massive processing power
The slow progress of artificial intelligence (AI) since first considered in the 1950s can largely be attributed to the constraints of traditional computing architectures, particularly the central processing unit (CPU), which struggles to handle the massive computational demand of modern AI algorithms.
AI workloads require processing power measured in petaflops (quadrillions of floating-point operations per second). Even the most advanced CPUs can only deliver a few teraflops (trillions of operations per second) at best.
This gap has paved the way for the graphics processing unit (GPU), originally designed for accelerating graphics, to emerge as a powerful alternative. Capable of delivering performance on the scale of petaflops, GPUs have become instrumental in driving AI forward. However, despite their advantages, GPUs also present limitations that continue to challenge the realization of AI’s full potential.
Crucial attributes for AI processing
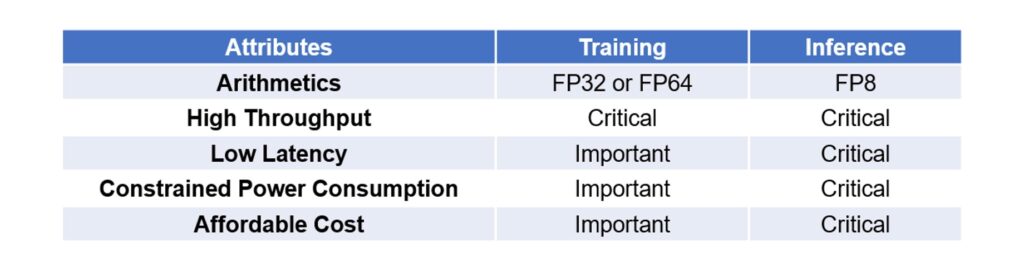
Deploying an AI/ML application involves two critical phases: training and inference.
Challenges during training
During the training phase, AI models learn to recognize patterns by processing vast datasets. The more data the model processes, the more accurate its responses become. Training these models is computationally intensive, often requiring continuous operation for weeks or even months, especially for transformer-based algorithms like OpenAI’s GPT-4, which can have over one-trillion parameters.
This process primarily relies on large arrays of GPUs to meet the massive computational demands. However, GPUs are not highly efficient when handling large language models (LLMs) given memory bandwidth limitations, i.e., the memory wall. As a result, GPUs may utilize only a small fraction of their theoretical processing power. For example, a GPU rated at one petaflop may achieve only 5% efficiency, effectively delivering just 50 teraflops. To compensate for this low efficiency, the industry scales by adding more processors. In this scenario, achieving an effective output of one petaflop would require 20 one-petaflop processors running in parallel.
Scaling up with more processors comes with its own challenges. Power consumption increases proportionally with the number of processors, as does the cost of hardware. For instance, the current Nvidia DGX GB200 NVL72 GPU rack consumes 120 kW, a power load that not all data centers can support. Nvidia estimates that training a model with 1.8-trillion parameters like GPT-4 requires around 2,000 of its latest Blackwell B200 GPUs that would consume up to four megawatts of power. Despite these inefficiencies, this remains the best available solution for training models of this scale.
Challenges during inference
Once a model reaches the desired level of accuracy, it transitions to the inference stage where it is deployed to make real-time predictions (in predictive AI applications) or generate decisions (in generative AI applications).
Unlike training, which prioritizes raw computational power regardless of cost, inference demands a more balanced and strategic approach focused on four critical factors that must be optimized simultaneously: efficient processing power, low latency, low power consumption, and low cost.
Balancing these factors is crucial for the effective deployment of AI models in real-world applications where performance and practicality are key:
- Efficient processing power: Ensures the model can operate effectively on available hardware, delivering the required performance without overburdening resources.
- Low latency: Enables fast response times, essential for real-time applications such as autonomous driving, virtual assistants, or interactive systems.
- Low power consumption: Critical for energy efficiency, particularly in edge devices, mobile applications, and IoT environments where power resources are limited.
- Low cost: Necessary for the broad adoption of AI technologies, especially in mobile, edge, and IoT applications where hardware costs must be minimized.
These four factors are interconnected, and compromising any one of them can negatively impact the overall effectiveness and feasibility of AI deployment. A common challenge across all four is rooted in memory implementation, which often becomes a bottleneck, limiting the performance of AI systems during inference.
Table II summarizes the differences between training and inference based on five attributes.
Conclusion
Currently, the AI training phase is largely dominated by a single industry leader that provides the specialized hardware and infrastructure required to train complex neural networks at scale.
Despite advancements, existing solutions for accelerating inference still fall short of fully addressing the critical requirements of efficiency, cost, scalability, and performance. The growing demand for more efficient processing technologies remains a pressing challenge.
Amid this search for optimized, cost-effective, and scalable inference solutions, a French startup has introduced a groundbreaking architecture. Its design replaces the traditional hierarchical memory structure with a large high-bandwidth memory composed of 192 million registers, all accessible within a single clock cycle (see Figure 2).
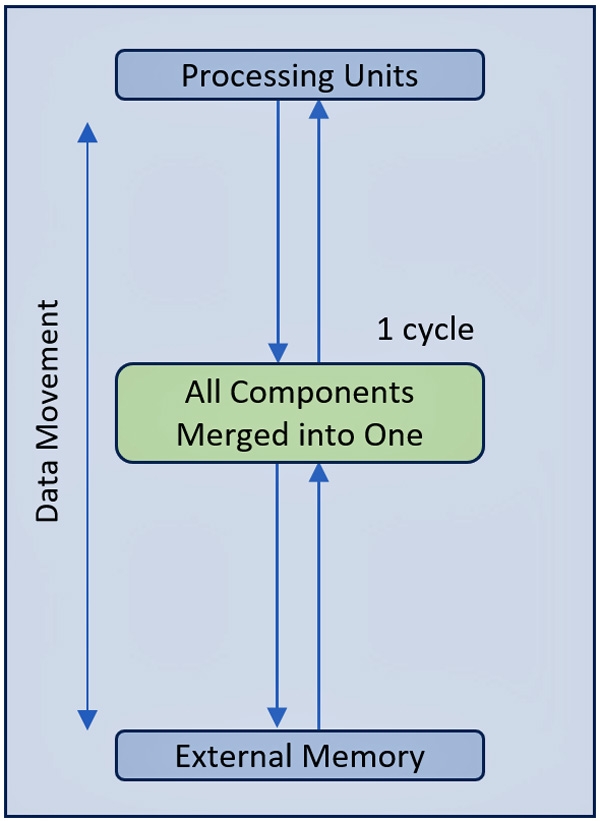
This single-cycle memory access enables significantly faster execution speeds, reduces latency, and minimizes power consumption. Additionally, the design requires less silicon area, allowing for higher processor utilization even in the most demanding applications that translates in lower cost.